Java 多线程
随着多核芯片逐渐成为主流,大多数软件开发人员不可避免地需要了解并行编程的知识。而同时,主流程序语言正在将越来越多的并行特性合并到标准库或者语言本身之中。我们可以看到,JDK 在这方面同样走在潮流的前方。从JDK 5到JDK 7,越来越多的线程相关的新API加入到了标准库中,为不同场景下对线程实现与调度提供了完善的支持。我们可以充分利用这些类库,来提高开发效率,改善程序性能。
Java中使用线程
Java的多线程基于以下两个重要的机制:
- 父线程结束,如果子线程正在运行,子线程不会跟着结束。
- 每个线程拥有一个线程栈,会维护引用,用于GC。
Java提供了以下两种常用的方式来使用多线程:
- 继承
Thread类 - 实现
Runnable接口
继承Thread类
class MyThread extends Thread {
@Override
public void run() {
}
}
Thread t = new MyThread();
t.start();
实现Runnable接口
class MyThread implements Runnable {
@Override
public void run() {
}
}
MyThread mt = new MyThread();
Thread t = new Thread(mt);
t.start();
需要注意的是:一个线程只能start()一次,如果多次调用start()方法,会出现Java.lang.IllegalStateException。
两种方式的区别在于继承Thread方式是每次都会创建一个MyThread对象,而如果采用实现Runnable接口的方式,可以使用同一个MyThread对象来创建多个线程,便于线程间共享内存。因此,设计线程间的数据共享时,一般应当采用实现Runnable接口的方式。
Callable与Future
java.util.concurrent包中还提供了一个Callable接口来实现线程,使用Callable需要与Future类配合使用。
public class TEMP {
public static void main(String[] args) throws Exception {
FutureTask<Integer> task = new FutureTask<>(new FF());
new Thread(task).start();
System.out.println("main thread");
System.out.println(task.get());
}
}
class FF implements Callable<Integer> {
@Override
public Integer call() throws Exception {
Thread.sleep(2000);
System.out.println("ff thread");
return new Random().nextInt(100);
}
}
程序运行的输出为:
main thread
ff thread
34
Callable接口与Runnable接口类似,不同的是,call方法是可以有返回值的,并且可以抛出异常。如果没有System.out.println(task.get()),那么主线程在运行完System.out.println("main thread")就会结束,但是因为有task.get(),因此,主线程会等待Callable线程执行完毕。
与Callable-Future类似的一个方法是回调(callback)。在子线程结束时调用父线程的方法来通知父线程。
一般Callable/Future与ExecutorService配合使用。使用ExecutorService来运行Callable线程:
ExecutorService exec = Executors.newCachedThreadPool();
// exec = Executors.newFixedThreadPool(3 /* nThread */);
exec.submit(new Callable<Integer>() {
@Override
public Integer call() throws Exception {
// ...
return null;
}
});
// exec.shutdown();
ExecutorService也可以用来执行实现Runnable线程:
exec.submit(new Runnable() {
@Override
public void run() throws Exception {
// ...
}
});
使用ExecutorService时,可以通过FutureTask来获取Callable线程call方法的返回值:
ExecutorService exec = Executors.newCachedThreadPool();
FutureTask<Integer> task = new FutureTask<>(new Callable<Integer>() {
@Override
public Integer call() throws Exception {
// ...
return null;
}
});
exec.submit(task);
Integer result = task.get();
ExecutorService还可以取消(cancel)一个Task(FutureTask)。
简单的线程同步
Java提供了强制原子性的内置锁机制:synchronized块。一个synchronized块有两部分:所对象的引用以及这个锁保护的代码块。内置锁在Java中扮演了互斥锁(mutex)的角色。内置锁匙可重入的(Reentrant)。通常使用synchronized关键字来进行线程间的同步。synchronized有两种用法:修饰方法和修饰代码块。
修饰方法
可以使用synchronized关键字来修饰类中的方法,从而达到线程间同步的目的。示例:
class A {
public synchronized void Func() {
// ...
}
}
synchronized关键字修饰方法表明该方法在运行期间将会对this加锁,也就是说,当方法Func运行时其他方法无法操作this对象。需要注意的是,synchronized与static关键字是可以共存的。
修饰代码块
synchronized关键字除了用来修饰方法,还可以用来修饰代码块:
class A {
Integer i;
// ...
public void func() {
// ...
synchronized(i) {
// ...
}
}
}
这表明在synchronized中的代码块运行期间将会占有锁this.i。synchronized修饰方法等价于下列写法:
class A {
public void Func() {
synchronized(this) {
// ...
}
}
}
可以看到,synchronized修饰代码块与修饰方法类似,但控制粒度更细,同步开销也较小。但是,在尽量减小同步代码块规模时应该注意原子操作中的语句必须在同一个同步代码块中。
静态方法同步
要同步静态方法,需要一个作用于整个类对象的锁。这个锁就是类自身。举例:
class A {
public static void func() {
synchronized(B.class) {
// ...
}
}
}
可重入锁
另一个需要注意的地方是Java的同步锁匙可重入锁,例如,递归调用run方法或者调用的函数有同样的synchronized锁并不会造成死锁。示例如下:
class KK extends Thread {
static Integer x = 10;
@Override
public void run() {
synchronized (x) {
if(x > 5) {
x -= 1;
System.out.println(x);
run();
}
}
}
}
wait, notify, notifyAll,join是常用的线程控制调度方法。
共享对象可见性和volatile
一种常见的错误观念认为只有写入共享变量是才需要同步,其实并非如此。volatile是一个声明,volatile关键字表示内存可见,volatile声明的变量不会被copy到线程的本地内存(缓存、缓冲区、寄存器,Cache等)中,而是直接在主存上进行操作。每次使用前从主存中读取新值,修改后立即写入主存,这用于防止线程间因寄存器和缓存引起的肮脏数据的读取和使用。
进一步的,JVM的规范里并没有要求volatile关键字修饰的变量一定不能被copy到线程的本地内存中,而是要求对其读写需要遵循happens-before语义,类似于互斥锁。同时,volatile还涉及到编译器的指令重排和CPU的重排序等等(影响变量之间的访问顺序)。
有些时候,可能一个线程只需要读一个变量的值,这时也有可能需要使用volatile的方式来防止出现同步错误。但需要注意的是,volatile不能和final一起共同修饰一个变量,因为final变量是不可改的。
Lock/Condition机制
Lock是控制多个线程对共享资源进行访问的工具。通常,锁提供了对共享资源的独占访问,每次只能有一个线程对Lock对象加锁,线程开始访问共享资源之前应先获得Lock对象。不过某些锁支持共享资源的并发访问,如:ReadWriteLock(读写锁),在线程安全控制中,通常使用ReentrantLock(可重入锁)。使用该Lock对象可以显示加锁、释放锁。
使用Lock的一般框架:
Lock lock = new ReetrantLock();
lock.lock();
try {
// ...
}
finally {
lock.unlock();
}
注意,try中的语句块是可能抛出异常的,因此,如果可能有异常抛出,那么lock.unlock()必须在finally语句块中,以确保JVM会释放锁。通常认为:Lock提供了比synchronized方法和synchronized代码块更广泛的锁定操作,Lock更灵活的结构,有很大的差别,并且可以支持多个Condition对象。
Condition的功能更类似于传统多线程技术中的Object.wait()(Condition.await())和Object.notifyAll()(Condition.signal()),用于实现线程间通信,一个Lock锁可以支持多个Condition。
一个使用Lock/Condition机制的例子:
class AA implements Runnable {
Lock lock = new ReentrantLock();
@Override
public void run() {
lock.lock();
System.out.println("get lock");
// ...
System.out.println("release lock");
lock.unlock();
}
}
在这里面,可以配合使用Condition完成较复杂的线程管理和调度。在Java多线程之Condition接口的实现一文中,作者使用Condition/Lock机制来实现了经典的“生产者-消费者”调度模型。在很多情景下,Condition提供了一种更加高效的、更有针对性的线程调度和同步方式。
BlockingQueue的使用
BlockingQueue,阻塞队列。BlockingQueue是一种特殊的Queue,若BlockingQueue是空的,从BlockingQueue取东西的操作将会被阻断进入等待状态直到BlocingkQueue进了新货才会被唤醒。同样,如果BlockingQueue是满的任何试图往里存东西的操作也会被阻断进入等待状态,直到BlockingQueue里有新的空间才会被唤醒继续操作。
BlockingQueue提供的方法主要有:
-
add(anObject): 把anObject加到BlockingQueue里,如果BlockingQueue可以容纳返回true,否则抛出IllegalStateException异常。 -
offer(anObject): 把anObject加到BlockingQueue里,如果BlockingQueue可以容纳返回true,否则返回false。 -
put(anObject): 把anObject加到BlockingQueue里,如果BlockingQueue没有空间,调用此方法的线程被阻断直到BlockingQueue里有新的空间再继续。 -
poll(time): 取出BlockingQueue里排在首位的对象,若不能立即取出可等time参数规定的时间。取不到时返回null。 -
take(): 取出BlockingQueue里排在首位的对象,若BlockingQueue为空,阻断进入等待状态直到BlockingQueue有新的对象被加入为止。
根据不同的需要BlockingQueue有4种具体实现:
ArrayBlockingQueue
规定大小的BlockingQueue,其构造函数必须带一个int参数来指明其大小。其所含的对象是以FIFO(先入先出)顺序排序的。
LinkedBlockingQueue
大小不定的BlockingQueue,若其构造函数带一个规定大小的参数,生成的BlockingQueue有大小限制。若不带大小参数,所生成的BlockingQueue的大小由Integer.MAX_VALUE来决定。其所含的对象是以FIFO(先入先出)顺序排序的。LinkedBlockingQueue和ArrayBlockingQueue比较起来,它们背后所用的数据结构不一样,导致LinkedBlockingQueue的数据吞吐量要大于ArrayBlockingQueue,但在线程数量很大时其性能的可预见性低于ArrayBlockingQueue。
PriorityBlockingQueue
类似于LinkedBlockingQueue,但其所含对象的排序不是FIFO,而是依据对象的自然排序顺序或者是构造函数所带的Comparator决定的顺序。
SynchronousQueue
特殊的BlockingQueue,对其的操作必须是放和取交替完成的。
BlockingQueue特别适用于线程间共享缓冲区的场景。BlockingQueue的四种实现也能够满足大多数的缓冲区调度需求。
Fork/Join
Fork/Join机制是JDK 7新增加的多线程框架,如果一个应用能被分解成多个子任务,并且组合多个子任务的结果就能够获得最终的答案,那么这个应用就适合用 Fork/Join 模式来解决。下图可大概说明Fork/Join模式的结构:
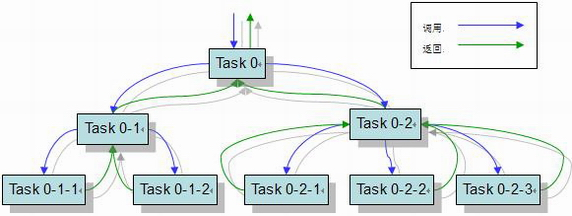
Fork/Join框架的几个核心类:
- ForkJoinPool: 线程池实现。实现了Work-stealing(工作窃取)算法,线程会主动寻找新创建的任务去执行,从而保证较高的线程利用率。程序运行时只需要唯一的一个ForkJoinPool。
- ForkJoinTask: 任务类,有两个子类实现具体的Task:
- RecursiveAction: 无返回值;
- RecursiveTask: 有返回值。
使用Fork/Join
首先,我们需要为程序创建一个ForkJoinPool:
Creates a ForkJoinPool with parallelism equal to java.lang.Runtime.availableProcessors,
private static ForkJoinPool pool = new ForkJoinPool();
这儿ForkJoinPool的构造函数有重载方法,可以通过参数设置线程数量(并行级别,parallelism level)以及ThreadFactory。
Task类需要实现compute方法,ForkJoinTask的代码框架:
If (problem size > default size){
task s = divide(task);
execute(tasks);
}
else {
resolve problem using another algorithm;
}
无返回值Task的示例
通过并行,将一个数组中每个元素的值都置为其索引值,即令a[i] = i。
class Task {
// Creates a ForkJoinPool with parallelism equal to
// java.lang.Runtime.availableProcessors,
private static ForkJoinPool pool = new ForkJoinPool();
private static final int default_size = 10;
public void solve() {
System.out.println("available processor number: " +
java.lang.Runtime.getRuntime().availableProcessors());
int[] a = new int[100];
SubTask task = new SubTask(a, 0, 100);
System.out.println("task start!");
pool.invoke(task);
System.out.println("task finish!");
}
class SubTask extends RecursiveAction {
int[] a;
int l, r;
public SubTask(int[] a, int l, int r) {
this.a = a;
this.l = l;
this.r = r;
}
@Override
protected void compute() {
System.out.println("Thread id: " + Thread.currentThread().getId());
if (r - l > BB.default_size) {
int mid = (l + r) / 2;
invokeAll(new SubTask(a, l, mid + 1), new SubTask(a, mid, r));
}
else {
for (int i = l; i < r; ++i) {
a[i] = i;
}
}
}
}
}
有返回值的Task
如果子任务有返回值,只需要改成继承RecursiveTask类,然后compute方法返回对应类型的返回值即可。例如:
class SubTask extends RecursiveTask<Integer> {
public Integer compute() {
// ...
}
}
SubTask task = new SubTask(...);
Integer result = task.get()
在fork子任务时,只需要:
SubTask t1 = new SubTask(...);
SubTask t2 = new SubTask(...);
invokeAll(t1, t2);
try {
result = t1.get()+t2.get();
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
return result;
异步执行Task
上面两个示例都是同步执行的,invoke与invokeAll都是阻塞当前线程的。当Task线程运行时会阻塞父线程,而在很多场合,我们需要Task线程异步执行。这是需要使用到execute或者submit方法。execute方法直接执行task,而submit方法是将task提交到任务队列里边去。而shutdown方法则表示线程池不再接收新的task(ForkJoinPool是有守护线程的)(shutdown之后再submit后产生RejectedExecutionException)。ForkJoinPool线程池提供了execute()方法来异步启动任务,而作为任务本身,可以调用fork()方法异步启动新的子任务,并调用子任务的join()方法来取得计算结果。通过通过task.isDone()方法来判断任务是否结束。
public boolean allDone(List<SubTask> tasks) {
for(SubTask task: tasks) {
if(!task.isDone()) {
return false;
}
}
return true;
}
当使用Fork/Join框架时,如果主线程(main方法)先于task线程结束了,那么task线程也会结束,而不会等待执行完。这也是与Java中传统的Thread/Runnable有区别的地方。至于原因,应该是主线程(main方法)结束导致ForkJoinPool的守护线程结束了。此外,ForkJoinPool的awaitTermination方法也值得注意。execute/submit/fork/join也可以与invoke/invokeAll配合使用,来调整线程间的阻塞关系。
在JDK 7 中的 Fork/Join 模式一文中,作者使用Fork/Join模式实现了并行快速排序算法,很值得参考。其实Fork/Join与Callable/Future/ExecutorService挺像的,ExecutorService与ForkJoinPool的API也很类似,ForkJoinPool比ExecutorService多出了Work-stealing(工作窃取)算法的调度,线程池和服务(Service)的概念对应地也能很好。在Fork/Join机制中,Task也是可以取消(cancel)的。
invoke与fork差异
这两个方法有很大的区别,当使用同步方法,调用这些方法(比如:invokeAll()方法)的任务将被阻塞,直到提交给线程池的任务完成它的执行。这允许ForkJoinPool类使用work-stealing算法,分配一个新的任务给正在执行睡眠任务的工作线程。反之,当使用异步方法(比如:fork()方法),这个任务将继续它的执行,所以ForkJoinPool类不能使用work-stealing算法来提高应用程序的性能。在这种情况下,只有当你调用join()或get()方法来等待任务的完成时,ForkJoinPool才能使用work-stealing算法。
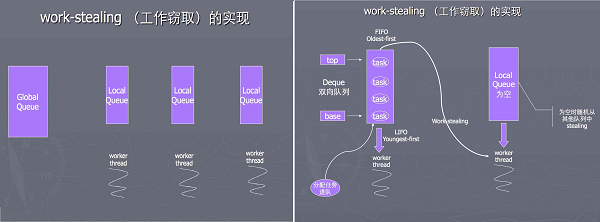
Work-stealing
工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。核心思想在于以下两点:
- 将一个任务分解为多个互不依赖的子任务。
- 当一个线程完成自己队列中的任务后,将其他线程的任务队列里的任务取出来执行。
Disruptor机制
单核情形下提高CPU利用率。
参考
- Java 理论与实践: 正确使用 Volatile 变量
- 用happen-before规则重新审视DCL
- Java多线程之Condition接口的实现
- ReentrantLock(重入锁)以及公平性
- JDK 7 中的 Fork/Join 模式
- java 7 fork-join framework and closures
- 聊聊并发(八)——Fork/Join框架介绍
- Java 理论与实践: JDK 5.0 中更灵活、更具可伸缩性的锁定机制
- Fork and Join: Java Can Excel at Painless Parallel Programming Too!
- Java线程之fork/join框架
- Java中不同的并发实现的性能比较
- Java并发的四种风味:Thread、Executor、ForkJoin和Actor