End-to-end Argument in System Design
The “End-to-end argument” says many functions in a communication system can only be completely and correctly implemented with the help of the applications at the end points. Cases in beyond distributed systems, like the fix for CEEs, are also amenable to the argument.
End-to-end Argument
End-to-end Argument in System Design, a paper published in 1984 by Saltzer, Reed, and Clark, presented a principle called the end-to-end-argument, which,
suggests that functions placed at low levels of a system may be redundant or of little value when compared with the cost of providing them at that low level. Low level mechanisms to support those functions are justified only as performance enhancements.
And says
The function in question can completely and correctly be implemented only with the knowledge and help of the application standing at the end points of the communication systems.
A follow-up paper 20 years later by Tim Moors, A critical review of “End-to-end arguments in system design”, looks at why many of the cited functions, e.g., encryption, duplicate message detection, and guaranteed message delivery, in the “end-to-end argument” paper did migrate into the communications substrate over time, due the advent of firewalls, caches, active networks, NAT, multicasting and network QOS. This paper shows the importance of trust as a criterion for deciding whether to implement a function locally or end-to-end.
Silent Data Corruptions on CPU
Application code always assumes to correctness of hardware, such as CPU, memory, etc. Then what would happen if the hardware corrupt silently?
Silent Data Corruptions (SDCs) is a know problem where data in main memory, on disk, or other storage is corrupted, without being immediately detected, e.g., the memory bit flips happen all the time12. Either you detect them, or you get silent data corruptions. Techniques like Error Correction Code (ECC) is widely used to reduce the error rate in SRAM. And, such protections are being brought to desktop chips from high-end servers3.
Two recent papers from Google, Cores that don’t count, and facebook, Silent Data Corruptions at Scale, both discuss the another source of SDCs, the Corruption Execution Erros (CEEs), is a systemic issue, and state that the computer, especially the cores that execute instructions, is NOT a fail-stop.
Those kind of errors, CEEs, can result in data loss, and the corruptions could propagate across the stack and manifest of application-level problems, as described in the picture below,
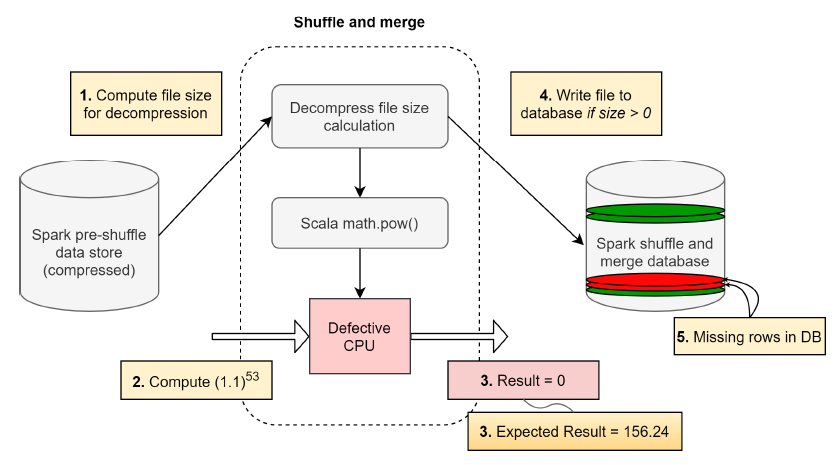
In one such computation, when the file size was being computed, a file with a valid file size was provided as input to the decompression algorithm, within the decompression pipeline. The algorithm invoked the power function provided by the Scala library (Scala: A programming language used for Spark). Interestingly, the Scala function returned a 0 size value for a file which was known to have a non-zero decompressed file size. Since the result of the file size computation is now 0, the file was not written into the decompressed output database.
Imagine the same computation being performed millions of times per day. This meant for some random scenarios, when the file size was non-zero, the decompression activity was never performed. As a result, the database had missing files. The missing files subsequently propagate to the application. An application keeping a list of key value store mappings for compressed files immediately observes that files that were compressed are no longer recoverable. This chain of dependencies causes the application to fail. Eventually the querying infrastructure reports critical data loss after decompression. The problem’s complexity is magnified as this manifested occasionally when the user scheduled the same workload on a cluster of machines. This meant the patterns to reproduce and debug were non-deterministic.
End-to-end Argument for CEEs at Scale
The assumption about “CPUs do dot have logical error” not always holds, and when the cluster become larger, the corruption execution errors becomes “reproducible”, and require months of debugging effort. As the hardware computational structures become more elaborate and increasingly specialized instruction-silicon pairings are introduced to improve performance, Reducing the negative impact on large-scale software infrastructure services of CEEs requires not only the hardware resiliency and actions to detect them, but also and more robust fault-tolerant software architectures.
When the lower layer of computation is not a fail-stop, the end-to-end argument applies to software design and implementation upon those hardwares, due to the lack of “trust”.